中文-Chinese
英语-English
首页
产品中心
通用计算产品
人工智能产品
自强®系列产品
应用型产品
存储产品
液冷产品
其他产品
解决方案
产品解决方案
行业解决方案
应用案例
互联网
交通
教育
金融
能源
医疗卫生
运营商
政府
制造业
其他
2024标杆案例
新闻中心
新闻公告
市场活动
产品推介
服务支持
服务支持
文档中心
固件中心
驱动下载
运维工具
生态认证
远程测试中心
生态合作
产品公告
如何购买
营销网络
项目咨询
宝德官方商城
关于宝德
公司简介
企业文化
联系我们
加入我们
新闻公告
市场活动
产品推介
拥抱大模型时代,共舞AI算力
时间:2023-07-05
来源:本站
宝德服务器
2023-07-05 18:13 广
今年以来,全球最火的“顶流”非大模型莫属。资料显示,ChatGPT掀起的AI 大模型热潮席卷到国内,国产大模型的发布争先恐后,数量总计达到 93 个,即将破百,中国大模型已然呈现“百模齐放”之势。
大模型需要处理大量数据,并进行海量复杂的计算,于是AI芯片市场烽烟雄起。早有NVIDIA 左手A800右手H800,被称为ChatGPT火爆以来的最大赢家,今年5月再次发布了GH200 Grace Hopper超级芯片和大内存AI超级计算机DGX GH200。紧随其后,6月苏妈隆重发布了MI300X芯片,在大语言模型上获得优势。芯片巨擘英特尔也早有布局和实践,以专攻AI计算的Habana® Gaudi®2和第四代至强可扩展处理器(MAX)等多样的硬件产品组合提供强大AI算力,6月底在MLCommons AI性能基准测试MLPerf训练3.0中展示了优异性能和卓越的性价比*。AI芯片技术竞赛继续火热进行中……
大模型非常依赖AI算力,但是绝对离不开CPU为主的通用算力。于是,AI服务器作为AI算力基础的重要设备需求激增。AI服务器专注于海量数据外理和运算方面,可以为人工智能,深度学习,神经网络,大模型等场景提供强大的动力并可广泛应用于医学、材料、金融、科技等千行百业。作为中国AI服务器的TOP3,宝德计算已经布局了完善的AI训练、AI推理和AI边缘的AI算力,并坚持携手上游AI芯片战略合作伙伴,学习吸收先进技术和产品,不断升级和完善强劲完善的AI算力基础设施。
大模型训练以宝德AI训练服务器PR4910E为佳
,它采用2颗身怀七大算力神器的第四代英特尔®至强®可扩展处理器,最大可达60核心,并具有13 个PCIe x16 Gen5插槽,支持10个全高全长双宽 GPU卡(NVIDIA® Tesla系列、英特尔®GPU Flex系列和昇腾Atlas系列等),可为大模型训练强有力的算力支撑;它支持32个 DIMM / DDR5内存插槽,支持最新400Gb ETH和NDR IB高速智能网卡,以及 GPU Direct RDMA,最多支持24个 NVMe SSD,且采用CPU 直通设计,大幅降低 I/O 延迟,这些都为大模型数据存储和传输提供高效可靠保证;此外,它采用整机模块化设计,支持灵活切换 CPU 和 GPU/TPU 的异构拓扑结构,方便用户维护和管理。
大模型推理用服务器则首推宝德自研双路服务器PR2715E
,它具有极致性能、卓越能效和能打的颜值,专注于高性能、云计算和数据中心等计算需求。同样采用2颗第四代英特尔®至强®可扩展处理器,提供强大的计算能力,支持DDR5、PCIe 5.0和HBM,性能提升高达50%;设有32个内存插槽,最大可支持8TB;它最大支持12个2.5”( 3.5”)和4个后置2.5 ”SATA/SAS/NVMe热插拔硬盘,或24个2.5”SATA/SAS/NVMe 和2个后置2.5 ”SATA/SAS热插拔硬盘,支持内置1个M.2(NVMe/SATA),保障了整机性能的强劲可靠;异构设计的系统,支持8张单宽 或者3张双宽GPU卡,拥有强劲的AI算力和安全性能。而且PR2715E具有智能散热系统、支持液冷散热,进一步帮助用户降低TCO。
此外,面对计算服务成本高和研发技术门槛高两大痛点,宝德提供了
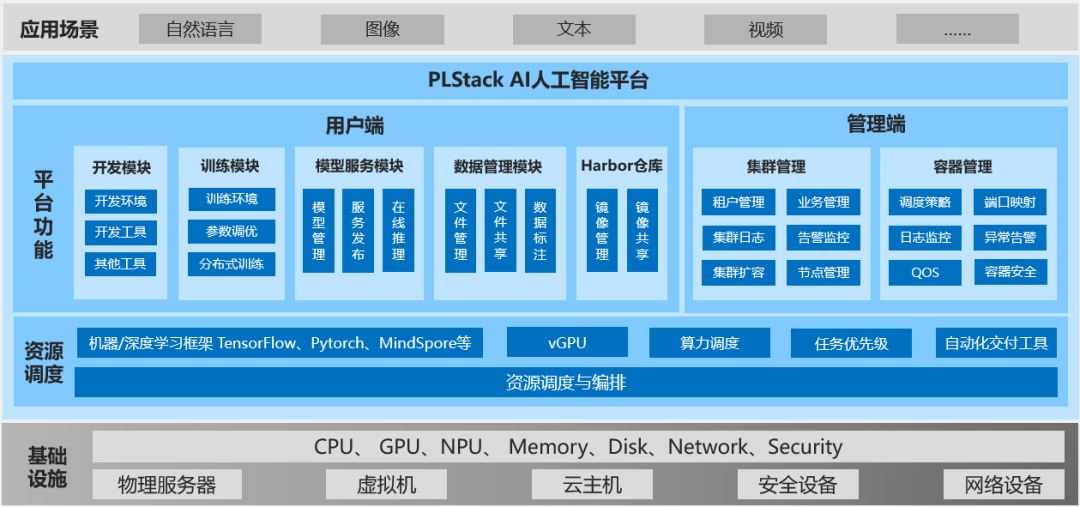
人工智能管理平台PLStack
,它基于 Docker + K8s技术实现整合现有计算设备资源,更好的对资源进行分配、管理、调度和监控。一方面,缓解深度学习算法训练的瓶颈,提高资源利用率,从而释放人工智能的全新能力;另一方面,降低 AI 技术门槛,释放AI 技术潜力,帮助用户将更多的精力集中到垂直应用的工作领域。而且,宝德PLStack平台支持多种主流深度学习框架(Tensorflow、PyTorch、Caffe 等),方便快速部署训练环境,并且支持多人在线实验,能够通过更直观的 UI 界面对资源进行高效管理。
如今,AI算力价格持续攀升、成本高居不下成为中国大模型发展面临的棘手问题,商业化转型日益紧迫,更加聚焦政务、金融、文娱、医疗、教育、汽车等行业的行业大模型和垂直大模型成为新的发展方向。大模型时代已来,AI算力共舞!
作为中国领先的算力产品方案提供商,宝德计算将继续发挥技术、市场和生态等整体优势,以性能强大、安全高效、应用适配和卓越性价比的AI产品和解决方案为中国更多的大模型发展和应用提供算力底座,共同助推中国人工智能产业的高速发展,赋能中国数字经济高质量发展!
*素材源于网络,如有侵权请联系删除
上一篇
下一篇
热门推荐
4008-870-872
点击咨询
产品中心
通用计算产品
人工智能产品
自强®系列产品
应用型产品
存储产品
液冷产品
其他产品
通用计算产品
人工智能产品
自强®系列产品
应用型产品
存储产品
液冷产品
其他产品
解决方案
产品解决方案
行业解决方案
产品解决方案
行业解决方案
应用案例
互联网
交通
教育
金融
能源
医疗卫生
运营商
政府
制造业
其他
2024标杆案例
互联网
交通
教育
金融
能源
医疗卫生
运营商
政府
制造业
其他
2024标杆案例
新闻中心
新闻公告
市场活动
产品推介
新闻公告
市场活动
产品推介
服务支持
服务支持
文档中心
固件中心
驱动下载
运维工具
生态认证
远程测试中心
生态合作
产品公告
服务支持
文档中心
固件中心
驱动下载
运维工具
生态认证
远程测试中心
生态合作
产品公告
关于宝德
公司简介
企业文化
联系我们
加入我们
公司简介
企业文化
联系我们
加入我们
宝德服务器
宝德自强
快速链接:
宝德控股
宝通集团
中青宝
金沙古酒
数广宝德
Copyright © 2021 宝德计算机系统股份有限公司版权所有
粤ICP备 17097175号-1
粤公网安备 44030902000103号













 4008-870-872
4008-870-872
